Announcing 1-bit Bonsai: The First Commercially Viable 1-bit LLMs
Today, we are announcing 1-bit Bonsai models that bring advanced intelligence to the devices where people actually live and work.
For the last decade, AI has advanced along a clear trajectory: to make smarter models, you make them bigger. More parameters, more GPUs, more power, more memory, and more cost. That approach worked. It gave us models that can reason across long contexts, solve difficult problems, and generate software, research, and creative work at remarkable quality.
But it also created a deep structural constraint on the future of AI: the most capable intelligence became trapped inside massive clusters and specialized infrastructure. Yet some of the most important uses of AI are not confined to data centers. They happen on phones, laptops, vehicles, robots, secure enterprise environments, and edge devices.
AI deployment no longer aligns with where it is needed. Today, that changes.
A New Path Forward: Concentrating intelligence
Today, we’re announcing PrismML, an AI lab building the most concentrated form of intelligence. Emerging from breakthrough research developed at Caltech, we’re guided by a core belief that the next major leaps in AI will be driven by order-of-magnitude improvements in intelligence density, not just sheer parameter count.
Concentrating intelligence means increasing the useful intelligence a model delivers per unit of size, power, and deployment footprint. This depends on several factors: the hardware the model runs on, the specifics of the workload, but, most critically, the size of the model. For this reason, at PrismML, we have focused on optimizing the Intelligence Density, the amount of intelligence a model can deliver per unit size (measured in GB). It’s a practical measure determining whether advanced AI remains locked inside expensive infrastructure or becomes available wherever it is needed.
Our new class of models is designed to unlock production-ready accuracy at the edge and our core technology will enable industry-changing intelligence in the cloud.
A true 1-bit model
1-bit Bonsai 8B implements a proprietary 1-bit model design across the entire network: embeddings, attention layers, MLP layers, and the LM head are all 1-bit. There are no higher-precision escape hatches. It is a true 1-bit model, end to end, across 8.2 billion parameters.
Despite being 14x smaller than the 8B (16-bit) full-precision models in its parameter-count class, it performs competitively on standard benchmarks while operating at radically higher efficiency.
That matters because model compression has historically come with painful tradeoffs. Low-bit models often lose too much capability in instruction following, multi-step reasoning, and reliable tool use to serve as the foundation for serious products. In practice, they fall short of being practically deployable.
Bonsai changes that. It shows that 1-bit models do not have to be narrow compromises. They can be capable, production-ready systems in their own right.
Intelligence Density
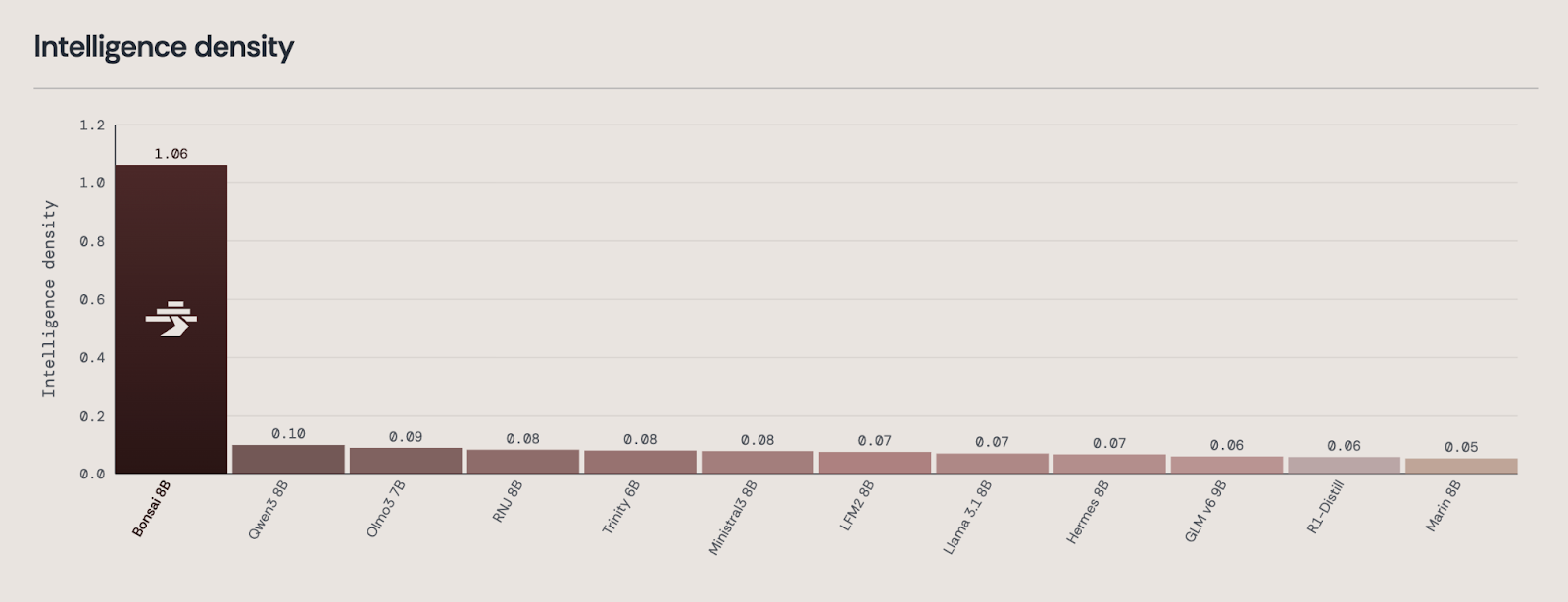
Across a broad benchmark suite, 1-bit Bonsai 8B delivers an improvement in the level of capability per model size that is not a marginal step forward, but rather a giant leap. To capture that rigorously, we measure intelligence density.
We define intelligence density as the negative of the log of the model’s average error rate (across the same benchmark suite) divided by the model size. Although this metric shows smaller gains for Bonsai than raw average benchmark scores would have (e.g. 10.6x vs 12.7x over Qwen3 8B), we believe it provides a more realistic view of intelligence. Unlike simple benchmark averages, it assigns greater value to improvements near high accuracy, where further gains are typically harder to achieve, than to equal-sized improvements at lower performance levels.
By that measure, 1-bit Bonsai 8B achieves an intelligence density score of 1.06/GB. Among nearby models by parameter-count, the closest, Qwen3 8B scores 0.10/GB. Bonsai is not just ahead on this measure; it is in a different regime.
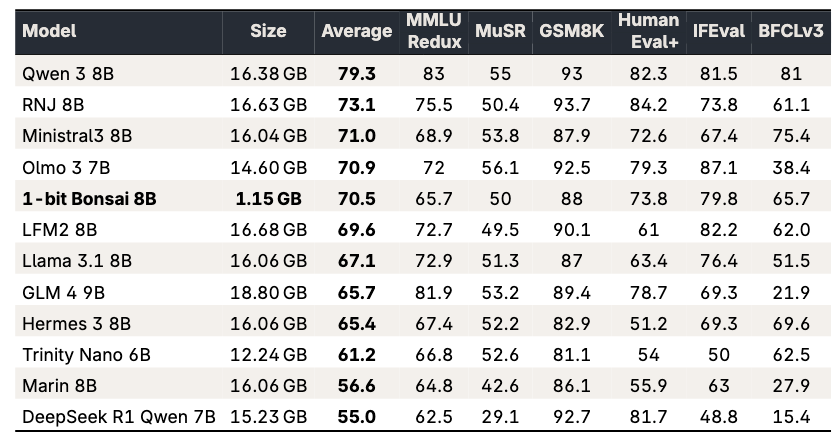
On raw benchmark averages, 1-bit Bonsai 8B remains competitive with leading 8B-class models, but it does so at just 1.15 GB memory footprint, roughly 12-14x smaller than its peers. That is the core of intelligence density: not just strong capability, but strong capability delivered in a radically more deployable form.
This is just the beginning of the category. Our upcoming generations will push the frontier of intelligence density.
What becomes possible when intelligence is this concentrated
When advanced models become small, fast, and efficient enough to run locally, the design space for AI changes immediately.
Products become more responsive because intelligence can run on-device, with far lower latency. Systems become more private because sensitive data no longer has to leave the device or cross organizational boundaries. Applications become more reliable because they are less dependent on constant cloud access. And AI becomes economically viable in settings where server-side deployment was previously too expensive.
Entirely new categories also begin to open up: persistent on-device agents, real-time robotics, secure enterprise copilots, offline intelligence, and AI-native products built for environments where bandwidth, power, or compliance constraints once made advanced models impractical.
This is why we view concentrated intelligence as more than an efficiency improvement. It expands the surface area of intelligence and therefore what AI products can be. The future of AI will not just be confined to the cloud. It will span cloud, edge, and everything in between.
Demo I: 1-bit Bonsai 8B running on an iPhone 17 Pro at approximately 40 toks/sec. A standard 16-bit 8B model cannot fit on any iPhone. For comparison, we also show a 16-bit 1B model running at 23 toks/sec on the same MATH-500 prompt, highlighting the substantial gap in both accuracy and speed.
Size and Speed
1-bit Bonsai 8B is only 1.15 GB. At that size, it is small enough to fit on an iPhone 17 Pro. Relative to models with similar performance, that represents roughly a 14x reduction in model size. That reduction is not cosmetic. It changes what hardware can host serious intelligence.
Across devices, Bonsai also delivers major throughput gains. On an M4 Pro Mac, it runs at 136 tokens per second. On an RTX 4090, it reaches 440 tokens per second. On an iPhone 17 Pro Max, it runs at roughly 44 tokens per second.
Demo II: 1-bit Bonsai 8B running on an M4 Pro Mac alongside a standard 16-bit 8B model.
From the demo above on M4 Pro, the difference is immediate: Bonsai uses a fraction of the memory while delivering substantially higher generation speed. Because the model can run locally, those gains come without unnecessary network latency. The result is an experience that feels fundamentally different from cloud-dependent AI: faster, more direct, and more available.
Demo III: 1-bit Bonsai 8B running on an M4 Pro Mac alongside a standard 16-bit 8B model, simulating a long-horizon agentic task running locally.
The advantage becomes even clearer on long-horizon agentic workloads. In the demo above, we simulate 50 ticket summary and assignment tasks. The 1-bit Bonsai 8B completes all 50 tickets, while the standard 16-bit 8B model does only 6 in the same window. For agents that must sustain reasoning over many steps, higher throughput and lower memory use do not just make the system faster - they expand the amount of work the agent can realistically do.
Energy Use
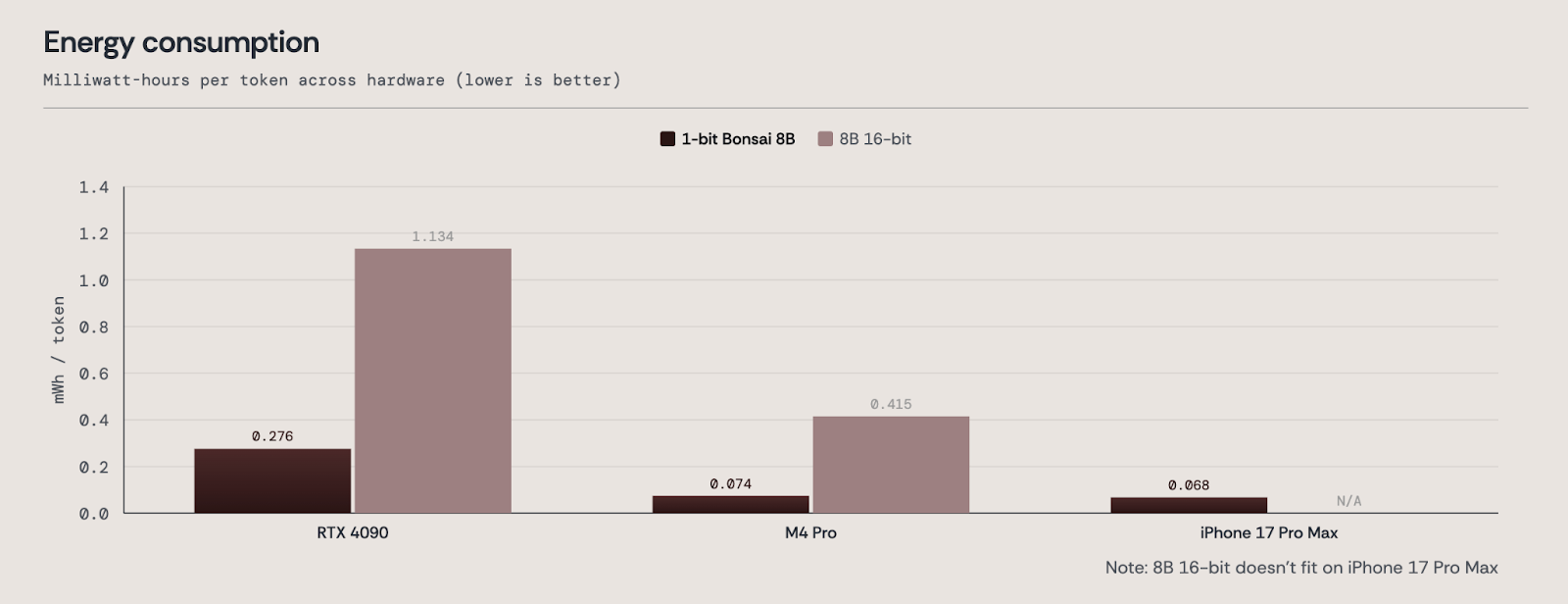
AI will only become foundational infrastructure if it becomes dramatically more efficient.
1-bit Bonsai 8B uses substantially less energy than its 16-bit full-precision counterparts, delivering roughly 4-5x better energy efficiency. On the M4 Pro, it requires 0.074 mWh/tok and on the iPhone 17 Pro Max, it only requires 0.068 mWh/tok.
This matters because energy efficiency is not just a system metric. It shapes the real economics of AI.
1-bit Hardware
The speedups and energy gains above are achieved on today’s standard commercial hardware, which was designed and optimized for full-precision arithmetic.
Importantly, these gains come primarily from the reduced memory footprint of 1-bit models, not yet from fully exploiting the 1-bit structure of the weights during inference. In other words, Bonsai already delivers substantial advantages on hardware that was not built for this class of model.
But 1-bit models also open the door to a deeper systems opportunity. In linear layers such as MLPs, 1-bit weights make it possible to perform inference with little or no multiplication, replacing much of the computation with simple additions. Hardware designed specifically for 1-bit inference could therefore push performance and energy efficiency much further, potentially by another order of magnitude.
Bonsai 4B and Bonsai 1.7B
To further demonstrate the power of our approach, we’re also releasing two smaller models: 1-bit Bonsai 4B and 1-bit Bonsai 1.7B. Both deliver strong throughput and energy efficiency while maintaining leading accuracy for their size.
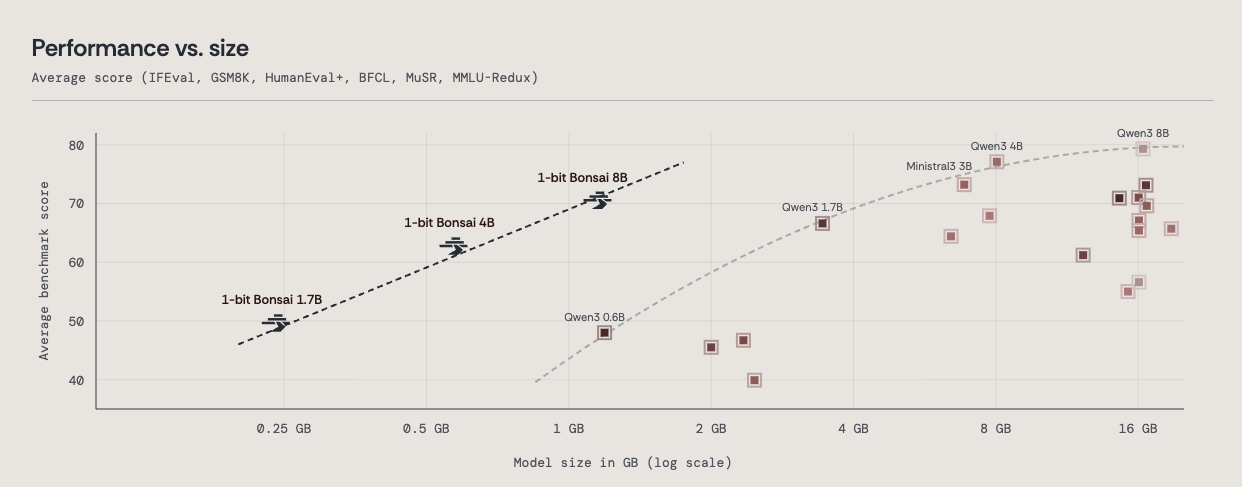
To further study the tradeoff between the size of a model and its average benchmark score, we considered 20 leading instruct models in sizes ranging from 1.2GB (Qwen3 0.6B) to 16.4GB (Qwen3 8B). The resulting scatter plot reveals a Pareto frontier of intelligence vs size, defined by the Qwen3 models 0.6B, 1.7B, 4B, and 8B, as well as the Ministral3 3B.
The 1-bit Bonsai 8B, along with its smaller sister models 1-bit Bonsai 1.7B and 4B, dramatically moves the Pareto frontier (of intelligence vs model size) to the left. This is now the new frontier.
The path from breakthrough to ubiquity
Human innovation often follows the same arc: first we prove something is possible, then we democratize it, making it smaller, cheaper, and accessible to everyone. Early computers filled entire rooms and cameras once required deliberate setups and long exposure times. Today, they live in our pockets.
This transition in AI has already begun. Over the next five years, models will continue to become more capable, but some of the most important progress will come from making intelligence portable enough, efficient enough, and deployable enough to live wherever it is needed.
That is the future PrismML is building toward.
Join Us
PrismML emerged from a team of Caltech researchers and was founded with support from Khosla Ventures, Cerberus and Google. We’ve spent years tackling one of the field’s hardest problems: compressing neural networks without sacrificing their reasoning ability.
If you want to help build the next generation of state-of-the-art AI, we’d love to hear from you. Check out our careers page.
Platform Coverage
We built 1-bit Bonsai models to operate on a wide spectrum of devices.
1-bit Bonsai 8B runs natively on Apple devices (Mac, iPhone, iPad) via MLX, on NVIDIA GPUs via llama.cpp CUDA. Model weights are available today under the Apache 2.0 License.
Full technical details of our training, evaluation, and benchmarking processes are available in our whitepaper.






%201.svg)

