
Introducing Ternary Bonsai: Top Intelligence at 1.58 Bits
Today, we’re announcing Ternary Bonsai, a new family of 1.58-bit language models designed to balance strict memory constraints with high accuracy requirements.
This release builds on the efficiency frontier we began exploring with the recently released 1-bit Bonsai models. The 1-bit family showed that extreme compression could still produce commercially useful language models. Ternary Bonsai targets a different point on that curve: a modest increase in size for a meaningful gain in performance.
The models are available in three sizes: 8B, 4B, and 1.7B parameters. By using ternary weights {-1, 0, +1}, these models achieve a memory footprint approximately 9x smaller than standard 16-bit models while outperforming most peers in their respective parameter classes on standard benchmarks.
A true ternary model
Ternary Bonsai implements 1.58-bit representation throughout the entire network architecture. There are no higher-precision escape hatches. Embeddings, attention layers, MLPs, and the LM head all use the same 1.58-bit representation.
The models employ a group-wise quantization scheme in which each weight is constrained to one of three values: {-s, 0, +s}. These three states are encoded as (-1, 0, +1) using 1.58 bits per weight, together with a shared FP16 scale factor (s) for each group of 128 weights.
Benchmark performance
Compared to the 1-bit Bonsai 8B, the Ternary Bonsai 8B scores 5 points higher on average across benchmarks, while requiring only 600MB more memory.
Ternary Bonsai 8B (1.75 GB) reaches 75.5 average benchmark score, compared with 70.5 for 1-bit Bonsai 8B (1.15 GB). Among its peers, it is only behind Qwen3 8B (16.38 GB) and outperforms all other models, despite being 9-10x smaller than them. It posts competitive results across MMLU Redux, MuSR, GSM8K, HumanEval+, IFEval, and BFCLv3, showing that the gain is broad rather than concentrated in a single benchmark.
Fig I: The benchmark scores of Ternary Bonsai 8B compared to other models in the same parameter class.
The intelligence density of Ternary Bonsai models continue to significantly outperform other models in their comparable parameter classes.
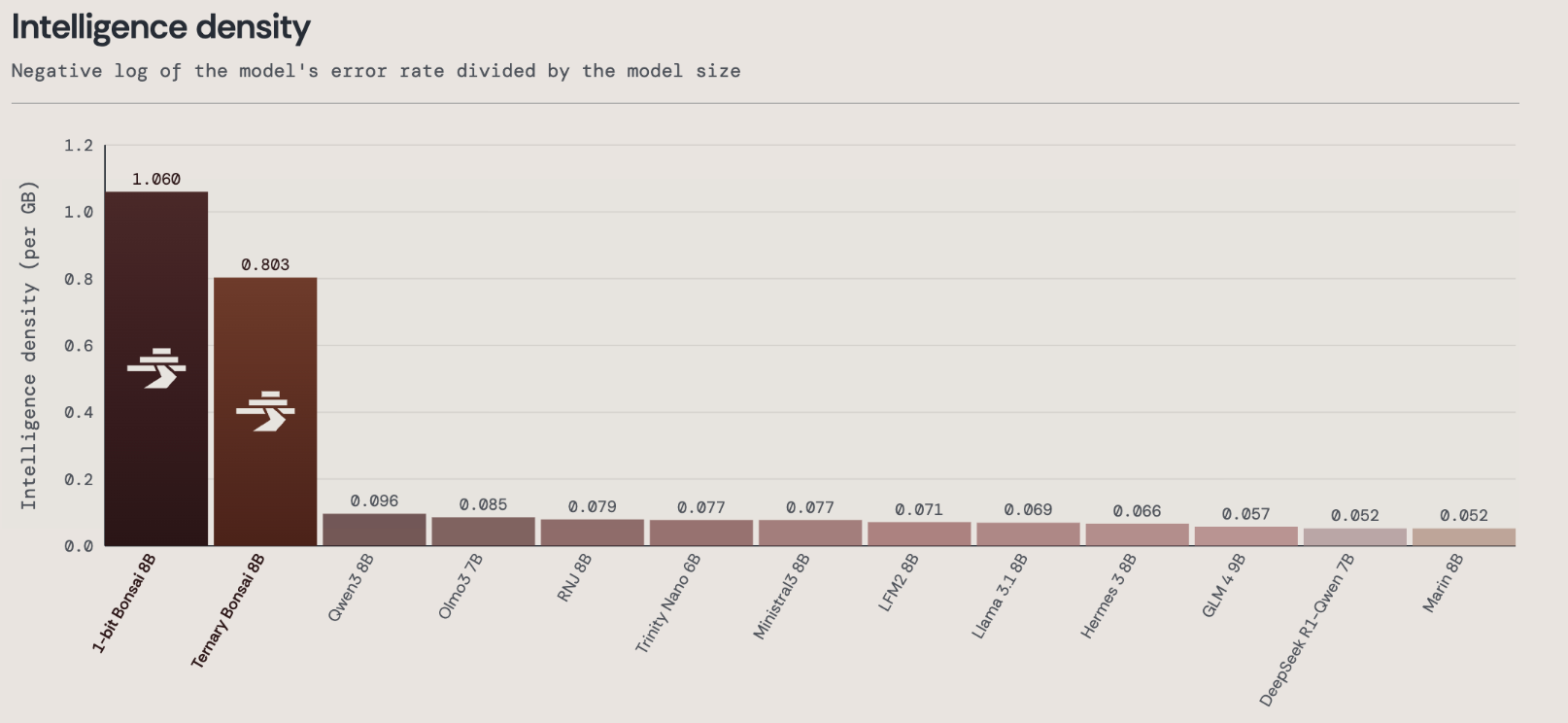
Extending the Pareto frontier
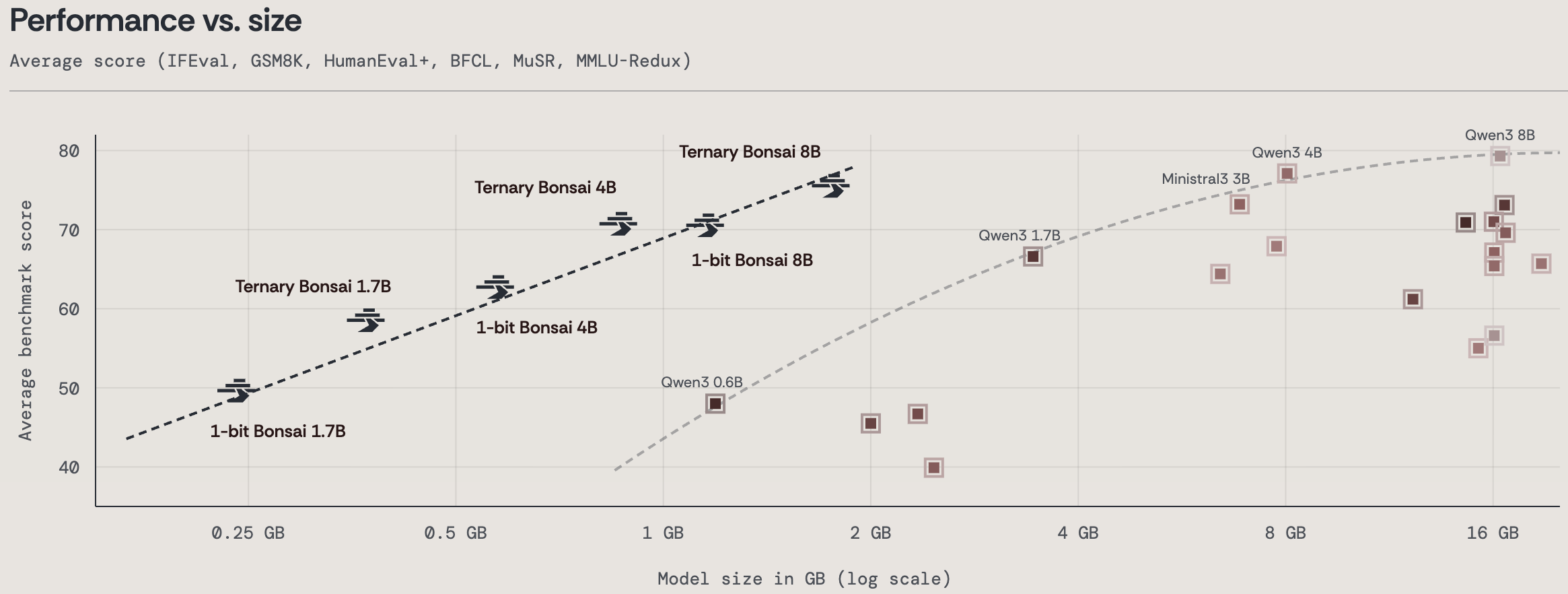
Our earlier 1-bit Bonsai models established a new Pareto frontier for language model capability versus size. Ternary Bonsai shifts that frontier even further left.
That makes it a useful addition to the Bonsai family, and not a replacement for 1-bit Bonsai. In settings where the smallest possible footprint is the priority, 1-bit remains the right choice. However, where a small increase in memory can justify a substantially stronger model, Ternary Bonsai offers an alternative tradeoff. The 1.7B, 4B, and 8B variants extend that tradeoff across multiple deployment tiers, giving developers more flexibility in how they allocate memory, throughput, and model quality.
Throughput and energy use
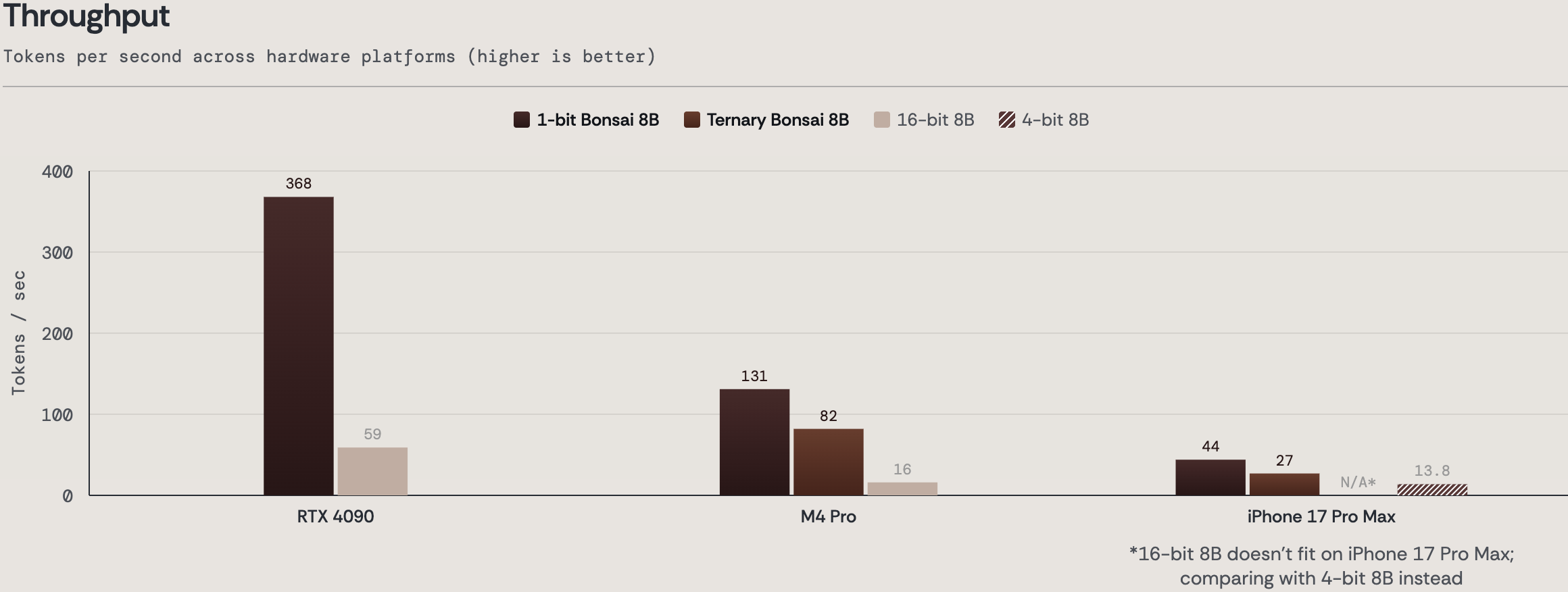
The new models also deliver strong throughput in practice. On M4 Pro, Ternary Bonsai 8B runs at 82 toks/sec, roughly 5x faster than a 16-bit 8B model and on iPhone 17 Pro Max, it runs at 27 toks/sec. They use substantially less energy than their 16-bit full-precision counterparts, delivering roughly 3-4x better energy efficiency. On the M4 Pro, Ternary Bonsai 8B requires 0.105 mWh/tok and on the iPhone 17 Pro Max, it only requires 0.132 mWh/tok.
Platform Coverage
Ternary Bonsai models run natively on Apple devices (Mac, iPhone, iPad) via MLX. Model weights are available today under the Apache 2.0 License.
Full technical details of our training, evaluation, and benchmarking processes are available in our whitepaper.
Join Us
PrismML emerged from a team of Caltech researchers and was founded with support from Khosla Ventures, Cerberus and Google. We’ve spent years tackling one of the field’s hardest problems: compressing neural networks without sacrificing their reasoning ability.
If you want to help build the next generation of state-of-the-art AI, we’d love to hear from you. Check out our careers page.


.svg)



%201.svg)

